Reducing Tight-Coupling
Heads Up!
This article is several years old now, and much has happened since then, so please keep that in mind while reading it.
These trends have filtered into the Umbraco Community as well, through talks on “Inversion of Control” by Lars-Erik Aabech or the super in-depth “SOLID CMS: SOLID Principles in CMS Development” article by the fantastic Emma Garland to name just a few.
While this is an encouraging movement to see, I believe we can still create cleaner solutions. So often I see Umbraco implementations where code is tightly ingrained with other features or parts of the application that it makes changing anything very difficult. It’s not difficult to realise that increased development difficulty also therefore means increased cost in the long run.
Commonly the “well built” Visual Studio solutions I see for Umbraco websites might look something a bit like this:
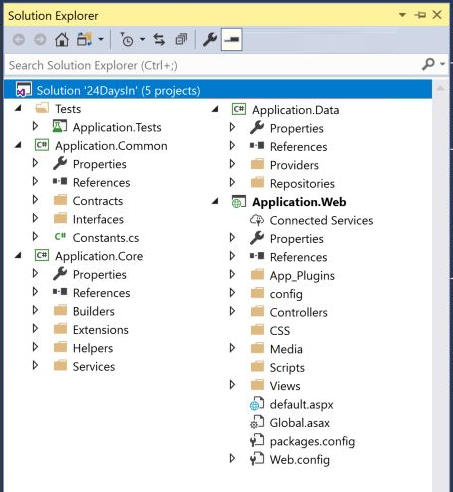
- *.Web: the entry point to the application and contains presentation-layer code (CSS, JS, Views)
- Umbraco is installed here
- *.Core: the application’s business logic, helpers and services
- Referenced by controllers in *.Web
- *.Data: database interaction, repositories
- Referenced by services in *.Core
- *.Common: shared data, structures, interfaces, constants
- Referenced in every layer
- *.Tests: automated tests (if we’re lucky!)
This is a good start as it separates the application into distinct logical layers – certainly better than putting everything in the *.Web project – but if we're not careful these projects can easily get bloated and messy as the codebase grows.
The downside of overly generic multi-purpose projects that are home to the large amounts of logic (like *.Core) is they can quickly become a dumping ground for all kinds of code. There’s nothing specifically wrong with the structure of each project (folders for helpers, services, etc), more the broad undefined scope of what's expected to reside within it. There’s little physical separation between code for individual features (beyond folders and naming) making it easy to misinterpret the purpose of a piece of code before changing it.
Because of the minimal physical separation between code it becomes easy to reference code from a separate feature within another thus creating a dependency on each other. As features become more intermingled bad habits like multiple classes per file emerge too, making things harder to find in the solution.
The moment you realise you’ve built something like this is when you set out to make one tiny change in one feature and ending up touching several classes containing other features and unrelated tests start failing… Chances are most developers have been guilty of building projects like this at some point, myself included…
Generic sounding class names, for example ContentHelper, that were once created for a given purpose are often morphed into a god-class spanning many different purposes. It seems a “helper” is the go-to place when a developer can’t think of the right place (read: too lazy to...) to put something!

Additionally as more code gets added to a project the number of dependencies that each of these projects has on external libraries likely grows too. These external libraries may actually only be needed by one class in that entire project, thus further bloating the project with things that don’t relate to 98% of its contents. The more dependencies installed the harder it is to keep track of what is being used, what needs upgrading and what that might impact, and can also make debugging assembly binding errors harder.
Scenario: eCommerce Store
Imagine the logic for a 24 Days In Umbraco eCommerce store selling festive t-shirts... We’ll need a way to find and purchase products, the site might have a search, and it should allow for credit card payments. It should probably also have a way of recording our customer’s contact details, and a way to update our CRM when they make a purchase.
24DaysStore.Web is our presentation layer where our CSS / JS / views sit, as well as where Umbraco is installed. The project has a dependency on 24DaysStore.Core for the business logic, models, services and helpers.
24DaysStore.Core probably looks something like this:
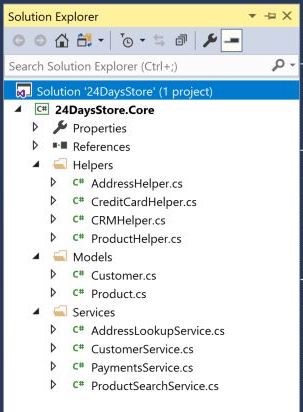
Even though this is a small project it already raises some questions about how easy it is to locate specific features or code. What does the ProductHelper class do? Where is the code that pushes data to the CRM? What should the Customer model be used for? Which classes depend on each other? As the complexity and size of this project grows these issues will be compounded.
Domain / Feature Projects
To combat these issues we can follow principles from Domain Driven Design (DDD) and separate each of our features into individual projects. These individual projects should only contain what is necessary for a given feature and should not depend on other projects in the system.
Better separation makes finding specific code easier, it aids sharing code between solutions and reusability of solutions and, done right, works to reduce inter-project dependencies. Furthermore the dependency tree for each of these domain / feature projects can be as small as possible, given only the libraries required for the specific feature's code to run are installed in it's project.
If we need the same functionality in another solution - no longer do we need to duplicate and maintain multiple variations of the same piece of code, it can instead be distributed as a standalone library and used in as many places as necessary. If we want to remove a specific feature from the application entirely it’s merely a case of removing the project from the solution, opposed to previously where we'd unpick several files across a whole project (potentially affecting other unrelated things unintentionally!).
Many other public libraries and products (including CMS!) on the market advocate similar practices to help developers keep dependencies between features to a minimum. Sitecore (yes… sorry… I said the S word!) has one of the most comprehensive examples of separating code into granular libraries with their recommended “Helix” design-principles, aimed at making it easier to develop, test and maintain applications.
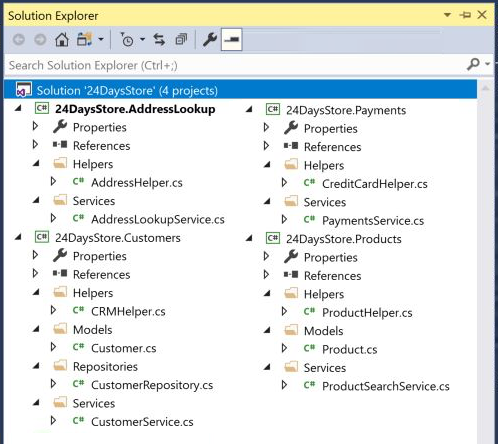
While for a small solution like in this example it may seem overkill to have so many projects I would argue getting in to the practice of creating properly separated / isolated features is healthy – plus you can avoid the inevitable messy refactor / restructure task further down the line once your codebase has grown.
Sharing Data
There are some scenarios where our features need to talk to each other, such as for passing the output / result of one action to another feature. Now our code is isolated in it’s own projects without dependencies on anything else we’re not able to call our other services directly – adding the project we wish to share data with as a reference would be a violation of the separation we have created.
Following the eCommerce store scenario; currently our CustomerService has a CreateCustomer method which we use to store customer data in to our database (via a repository class) and then post it off to our CRM (via a helper class).
public class CustomerService
{
public void CreateCustomer(Customer customer)
{
// create in database
_customerRepository.CreateCustomer(customer);
// post to CRM
crmHelper.Post(customer);
}
}This code works and is very clear, but the method is doing far more than it’s name would imply... The Single Responsibility Principle (the S in SOLID) says our code should serve a single purpose; in this case it’s to create a customer, but the code is also telling the CRM about that new customer. In reality the CRM interaction here is a separate feature as it’s not directly necessary in order for the customer to be created, more an additional consequence.
To avoid creating a tight coupling in scenarios like this we can use an application event containing the necessary data for another part of the application to perform what it needs to do – in this case passing the customer that the service creates to the CRM code running elsewhere within the application. Events are defined and “raised” within our services then the code to be triggered defined elsewhere. Most Umbraco developers will be quite familiar with hooking into CMS events such as onPublish, but perhaps won’t have raised and consumed events from their own code before – this works in the same way!
Even better, exposing an event means any part of the application can subscribe and listen to perform an action accordingly without the need to modify the logic of our service. Similarly if in future we decided the CRM call is no longer needed removing it is simply a case of unsubscribing from the event, rather than deleting code from our service.
Events
The “pattern” for what the output of your event should look like is defined in a delegate. Here we’ve created a delegate that passes our Customer model as a parameter so we use it whenever we need to pass a customer’s record along in an event.
public delegate void CustomerEvent(Customer customer);We define your event within our service class, specifying the CustomerCreated delegate we just created as its type.
public static event CustomerEvent CustomerCreated;Finally, we can raise the event in our service.
public class CustomerService
{
public static event CustomerEvent CustomerCreated;
public void CreateCustomer(Customer customer)
{
// create in database
customerRepository.CreateCustomer(customer);
if (CustomerCreated != null)
{
// trigger event
CustomerCreated(customer);
}
}
}The null check around the event is necessary as if there are no subscribers to our CustomerCreated event it will be null and won’t be able to execute.
We can now subscribe to your applications custom events within an ApplicationEventHandler. Our calls to the CRM code can be decoupled from all the unrelated logic in our CustomerService and instead performed when the CustomerCreated event fires.
public class 24DaysStore : ApplicationEventHandler
{
protected override void ApplicationStarted(...)
{
CustomerService.CustomerCreated += CustomerService_CustomerCreated;
}
private void CustomerService_CustomerCreated(Customer customer)
{
// post record to CRM
// send a welcome email
// ...
}
}Pro-tip: After a great chat with Lars-Erik at Umbraco Sweden Festival, he proposed using a handler pattern for raising and consuming events to make things even more decoupled!
Content Models
In an ideal scenario we would keep all of the models needed for a given feature within the corresponding projects, that includes Content Models representing document types in Umbraco.
By default Umbraco ships with ModelsBuilder enabled – it works by generating C# classes to represent document type configuration on the fly. When using Compositions it will generate an interface to represent the properties and ensure that the resulting class representing a document type implements that interface. The models it generates are available as a DLL, strongly typed objects in memory, or as *.cs files in your Visual Studio solution.
Within generated models there can be multiple dependencies on other Content Models, such as where a property returns another Content Model. The Umbraco.Web assembly (which brings with it a large number of other dependencies) is required to be installed in order for models to operate – we don’t want to be installing these everywhere Content Models are needed!
Given this, ModelsBuilder does not perfectly lend itself to spitting individual generated models out into their specific feature projects. But perhaps there’s a compromise that can be made... Content Models could be treated as a feature of our application in their own right, and therefore reside in their own project (e.g. 24DaysStore.Models.ContentModels) that can be referenced by individual features where need.
The Umbraco.ModelsBuilder.ModelsMode appsetting defines the format ModelsBuilder should output. When set to AppData, rather than producing a pre-built DLL, ModelsBuilder will generate *.generated.cs files inside the App_Code folder of our website that need to be compiled to be built.
An added benefit of storing physical files for the model definitions in the Visual Studio solution is being able to include then in source control and track changes over time – something that's not easily doable in either of the other "ModelsModes".
<add key="Umbraco.ModelsBuilder.ModelsMode" value="AppData" />As we don’t want our models within the website but rather a separate project, we need to define which path our classes should be generated into. We can define an alternative path to the default ~/App_Code directory in the Umbraco.ModelsBuilder.ModelsDirectory appsetting. Set the path to the location in the project you wish for the models to be generated.
Pro-tip: I personally prefer to keep my generated models within folder in the project, to make space in the root of the project and clearly separate them from any custom models I need to create.
The Umbraco.ModelsBuilder.AcceptUnsafeModelsDirectory appsetting must also be set to "true" in order to store the models outside of the website root (which in this case we do!)
<add key="Umbraco.ModelsBuilder.ModelsDirectory" value="~/../24DaysStore.Models.ContentModels/Generated" />
<add key="Umbraco.ModelsBuilder.AcceptUnsafeModelsDirectory" value="true" />Now we have our models within our separated project you may notice the namespace does not match the namespace of the project. The default namespace Umbraco.Web.PublishedContentModels is used. This can also be configured via an appsetting, like so:
<add key="Umbraco.ModelsBuilder.ModelsNamespace" value="24DaysStore.Models.ContentModels" />If you don't use ModelsBuilder or want a potentially purer solution for mapping Umbraco content to Content Models without relying on a shared library there are of course alternatives! Perhaps manually assigning properties from IPublishedContent to properties on the custom Content Model is sufficient, or maybe view-model mappers like Ditto or UmbMapper can help automate the process.
Takeaways
In summary: despite the ever growing awareness of better coding practices most Umbraco solutions still contain code that violates these principles, large numbers of dependencies, and messy inter-dependent code.
In short, my 3 takeaways for better architected solutions are:
- Ditch *.Core, *.Data, etc, projects! They make it hard to find code and can quickly become a place where anything goes. Instead isolate all the code for a specific feature by creating individual projects
- Don’t pass data / output between methods directly! Code with direct dependencies on other code is potentially error prone and can . Eliminating calls to unrelated code helps keep code cleaner too. Instead raise custom events to share the data you need and consume it elsewhere in the application
- Store your Content Model definitions in the Visual Studio solution! Separate models out into a separate project that can be shared across projects
There are still many additional ways solution architecture can be improved so don’t take this as a definitive list. It’s definitely a topic I feel is worth discussing more in-depth throughout 2019!
