AzureSearch and Media
Heads Up!
This article is several years old now, and much has happened since then, so please keep that in mind while reading it.
- Examine
- Solr
- Azure Search
We decided to use Azure search.
The main reason behind that decision is that it is scalable, a colleague was already using it on another project, the website was going to be hosted on Azure and the media files are saved in Azure Blob storage so that was a win-win.
This article will focus on getting Azure search to work with indexing media content in the likes of word docs and pdf’s. The indexing of media like this is not part of the base project we used to get AzureSearch working.
The Base
First of all the base of our code is the Azure Project by Darren Ferguson, which you can find here:
This gave us the basic gist of what we wanted to accomplish but still missed some elements we needed. We had to copy the project because at the time we started using it the package was not yet available. The major difference is that the project uses JSON to store its configuration. This did not work for us as that cannot be transformed in Visual Studio like XML can. So we replaced the JSON with a XML structure file.
After we changed the config from JSON to an XML structure we had the search up and running in no time, however we needed three more things that we not present in the project:
- Keyword highlighting
- Search PDF
- Search Office docs; Word & excel
The rest of this article will focus on the three functions mentioned above, and i will assume you have some knowledge about AzureSearch and Darrens Project. If you do not please read the readme file of Darrens Project.
Keyword Highlighting
Keyword Highlighting is a built in feature in Azure Search. So that’s just some config changes and we are good to go right? Well no you still need to do some minor coding.
There are two steps to take to activate it.
- Config.
- Display highlighted keywords
Config
First of all we need to tell Azure Search which indexed fields in can use as it’s source. This is done in the config file.
<HighlightFields>pageTitle,articleIntro,articleText,contentRowsPicker,mediaText</HighlightFields>
In the example above you can see the names of the fields we look have the keyword.
This is the first part, it tells Azure Search in what fields it can look for the keyword. Next we need to tell it how the Search result text should look like when it is present in one of those fields.
This can be done by setting the following parameters in the SearchParameters object.
The code below can be directly added to the “GetSearchParameters” method.
Right about here:
sp.HighlightPreTag = HttpUtility.HtmlEncode("<span class='highlight'>");
sp.HighlightPostTag = HttpUtility.HtmlEncode("</span>");
sp.HighlightFields = new List<string>();
if (!string.IsNullOrEmpty(this._config.HighlightFields))
{
var splitHighlightFields = this._config.HighlightFields.Split(',');
foreach (var field in splitHighlightFields)
{
if (!string.IsNullOrEmpty(field))
{
sp.HighlightFields.Add(field);
}
}
}Setup of the Highlights
Here we see three things:
- You can use any HTML you want to denote the keyword
- You have to HTML Encode the HTML because it will be passed to the AzureSearch API in HTML.
- We take the value from the config file, and add all the FieldNames to the HighlightFields list.
We have now added the basic config needed for Keyword Highlighting, now we need to make sure we display it.
Display
When looping through your search results we now have a choice.
We can either use the default Title and Text of a SearchItem, or if the searchItem has Highlights use them.
Now the standard SearchResult class did not have a “HitHighlights” property we added this.
When using Darrens project it’s best to add the property in the following class and interface
- https://github.com/darrenferguson/UmbracoAzureSearch/blob/master/Moriyama.AzureSearch.Umbraco.Application/Models/SearchResult.cs
- https://github.com/darrenferguson/UmbracoAzureSearch/blob/master/Moriyama.AzureSearch.Umbraco.Application/Interfaces/ISearchResult.cs
In our case we choose to loop through the search results and check if the “Highlights” property has any hits for highlights and if so loop through them and populate the fields we want/need.
// If we have highlights get a title and a text to show
if (searchResult.Highlights != null)
{
if (searchResult.Highlights.ContainsKey("pageTitle"))
{
title = System.Web.HttpUtility.HtmlDecode(searchResult.Highlights["pageTitle"].First());
}
foreach (var highlight in searchResult.Highlights)
{
if (!highlight.Key.Equals("pageTitle") && string.IsNullOrEmpty(text))
{
text = System.Web.HttpUtility.HtmlDecode(highlight.Value.First());
break;
}
}
}Get the highlights
So the code above fills 2 strings, title and text. These are passed to a model we use to display the results. Please note we are using HtmlDecode to decode the result we get from AzureSearch otherwise you wouldn’t get the keyword highlight HTML.
This also is a risk since the all text is HtmlDecoded, this would also mean that if you’re Text contains other HTML beside the HTML for the highlighting it will also be displayed and might break the presentation. Keep in mind when indexing the content!
For the non-dutch speakers, we see a searchresult with the keyword highlighted in the intro-text
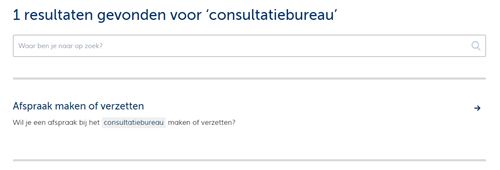
Indexing Media
Darren’s project has a method where it takes a Node and uploads it to the Cloud index. In this event you can alter what information is stored and where.
The event is Umbraco’s MediaService.Saved event.
In the ‘CustomApplicationEventHandler’ class there is the MediaServiceSaved method that triggers each time a Media node is saved in Umbraco.
The method is linked here:
The method reindexing the Media node can be found here:
The altering of information is done in the “FromUmbracoMedia” method which can be found here.
Unfortunately that method ‘only’ support general Media and does not save enough information to make certain media types searchable.
In our case we wanted to be able to search PDF and Office documents. To enable this I went for a simple approach, I wanted a single custom field called “mediaText” where I could store the contents of the files as plaintext.
To ensure the Azure Index would know this field you add it in the configuration like this:
<SearchField>
<Name>mediaText</Name>
<Type>string</Type>
<IsSearchable>true</IsSearchable>
</SearchField>
Please note the “IsSearchable” attribute, it denotes that the field can be searched if you do not add this and still search it it will result in an Exception.
Search PDF
When parsing a Media file for upload it is easy to check if it’s a PDF file.
When it’s a PDF use a ThridParty Tool to open the PDF and transform its contents to plain text.
For the PDF i used the free version of iTextSharp. It will easily let you open the PDF file read all the pages and put that content into a single string.
The code below shows how to get the contents, where the “content” item is a Umbraco IMedia object.
// this block of code is part of the "FromUmbracoMedia(IMedia content, IEnumerable<SearchField> searchFields)" method.
// IsPDF() is psudocode and should be replaced by a filetype check.
if (IsPDF())
{
var pdfContent = string.Empty;
var input = HostingEnvironment.VirtualPathProvider.GetFile(path).Open();
using (PdfReader reader = new PdfReader(input))
{
for (int i = 1; i <= reader.NumberOfPages; i++)
{
var pageContent = PdfTextExtractor.GetTextFromPage(reader, i);
pdfContent += pageContent;
}
}
result["mediaText"] = pdfContent;
}
Excerpt of how to read the PDF file
Running the code above will result in a AzureIndex where if the search element is a PDF file the “mediaText” field will be filled with the contents of the PDF for easy searching.
Search Office docs
The support of Office document was a bit harder since we had to support word and excel.
This required the use of the “DocumentFormat.OpenXml” Nuget package.
Again our goal is to have the document as a plaintext string and stored in the “mediaText” field in the index.
Word
After doing some impressive google-ing i found the following code.
// this block of code is part of the "FromUmbracoMedia(IMedia content, IEnumerable<SearchField> searchFields)" method.
var result = this.FromUmbracoContent((ContentBase)content, searchFields);
// getting an incorrect stream object, wich cases the document not to be indexed correctly
var umbracoFilePath = content.GetValue<string>(Umbraco.Core.Constants.Conventions.Media.File);
var path = "~" + umbracoFilePath;
// IsWordDoc() is psudocode. And should be replaced by a check on filetype.
if (IsWordDoc())
{
var input = HostingEnvironment.VirtualPathProvider.GetFile(path).Open();
var wordContent = string.Empty;
// Open a WordprocessingDocument for read-only access based on a stream.
using (WordprocessingDocument wordDocument = WordprocessingDocument.Open(input, false))
{
Body body = wordDocument.MainDocumentPart.Document.Body;
wordContent = GetPlainText(body);
}
result["mediaText"] = wordContent;
}
Excerpt of how to read a word file
The code above takes the Umbraco IMedia object’s ‘path’ and uses it to get the Stream to open it using the WordprocessingDocument.Open method.
After that a helper method “GetPlainText” will take the contents of the word document and transform it to plain text.
private string GetPlainText(OpenXmlElement element)
{
StringBuilder PlainTextInWord = new StringBuilder();
foreach (OpenXmlElement section in element.Elements())
{
switch (section.LocalName)
{
// Text
case "t":
PlainTextInWord.Append(section.InnerText);
break;
case "cr": // Carriage return
case "br": // Page break
PlainTextInWord.Append(Environment.NewLine);
break;
// Tab
case "tab":
PlainTextInWord.Append("\t");
break;
// Paragraph
case "p":
PlainTextInWord.Append(GetPlainText(section));
PlainTextInWord.AppendLine(Environment.NewLine);
break;
default:
PlainTextInWord.Append(GetPlainText(section));
break;
}
}
return PlainTextInWord.ToString();
}Transform a word element to a string
The method above gets a element and proceeds to go through all the elements it can find and adding the results to the StringBuilder.
The result of the StringBuilder will be saved in the Azure Index.
Excel
For excel we needed to use an other method of getting the content since it of course does not have pages we can loop through.
// this block of code is part of the "FromUmbracoMedia(IMedia content, IEnumerable<SearchField> searchFields)" method.
// ISExcel() is psudocode and should be replaced by a proper filetype check.
if (IsExcel())
{
var input = HostingEnvironment.VirtualPathProvider.GetFile(path).Open();
var excelContent = string.Empty;
using (SpreadsheetDocument doc = SpreadsheetDocument.Open(input, false))
{
WorkbookPart workbookPart = doc.WorkbookPart;
SharedStringTablePart sstpart = workbookPart.GetPartsOfType<SharedStringTablePart>().First();
SharedStringTable sst = sstpart.SharedStringTable;
WorksheetPart worksheetPart = workbookPart.WorksheetParts.First();
Worksheet sheet = worksheetPart.Worksheet;
var rows = sheet.Descendants<Row>();
foreach (Row row in rows)
{
foreach (Cell c in row.Elements<Cell>())
{
if ((c.DataType != null) && (c.DataType == CellValues.SharedString))
{
int ssid = int.Parse(c.CellValue.Text);
string str = sst.ChildElements[ssid].InnerText;
excelContent += " " + str;
}
else if (c.CellValue != null)
{
excelContent += " " + c.CellValue.Text;
}
}
}
}
result["mediaText"] = excelContent;
}
Excerpt of the way to read an excel file.
The code above takes the Umbraco IMedia item’s ‘path’ and turns it in a Spreadsheet object.
We can then get the first worksheet in that file and loop through all the rows and columns, each time adding the value of the cell to the ‘excelContent’ string.
The excelContent string is than later saved in the “mediaText” field in the AzureIndex.
Please note that when using this option to store the media as plain text you are increasing the size of your index quite fast ( depending on how much media you or your customers might upload ). This may require you to not use the free option of AzureSearch but go for the paid option(s).
I hope this article helps some of you when getting started with AzureSearch and Media.
