Umbraco edge case stories
Heads Up!
This article is several years old now, and much has happened since then, so please keep that in mind while reading it.
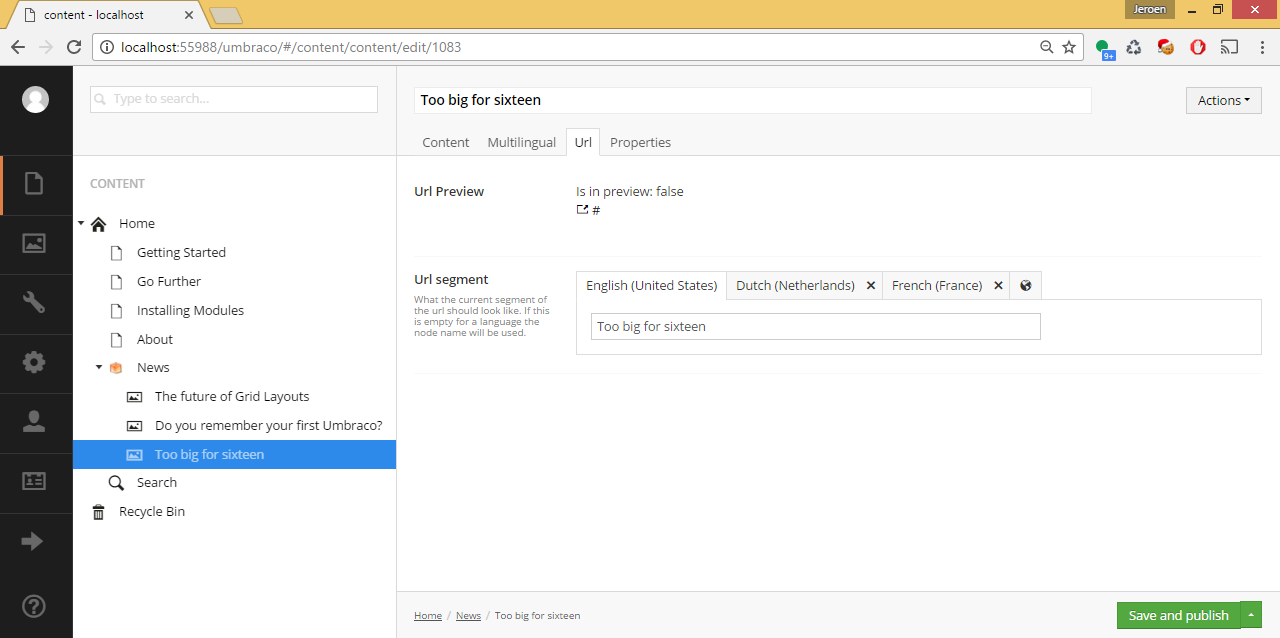
Preview all content
The story
When you press the preview button in Umbraco that page will go into preview. Also all subnodes of that node will go into preview. This means not the entire website is in preview. This could cause problems if you want to preview content which is not a subnode. For example if you have some nodes that have a UrlProvider and ContentFinder which are not hierarchical. So we needed a way preview all content.
The topic
I already had some ideas, but it's always good to discuss them so I started a topic called Preview all content.
Some time before that topic I also started a topic to move the available URLs to another tab instead of the last one.
The solution
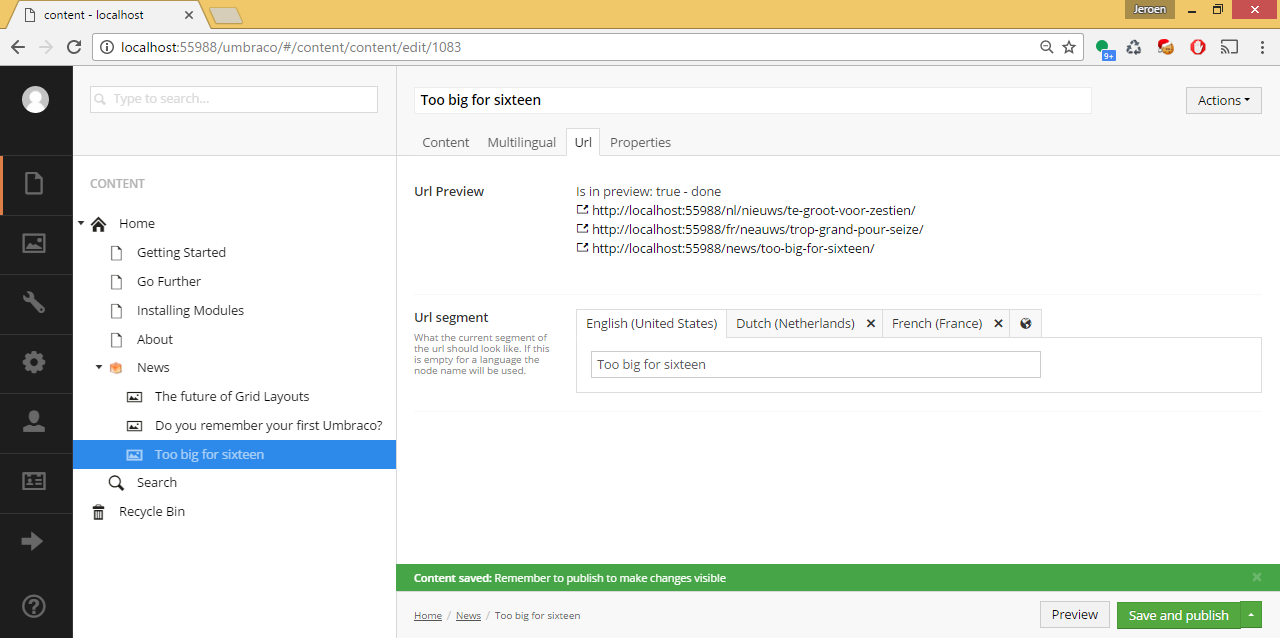
After looking at the Umbraco source code I discovered there is an API where you can pass an Id and the website will go into preview with all subnodes. So I fetched the highest node in the tree and always use that when going into preview. To make it a bit more user friendly this is done each time the save button is pressed. Yes this means each time someone saves the website will be in preview, but this is exactly what our content editors wanted.
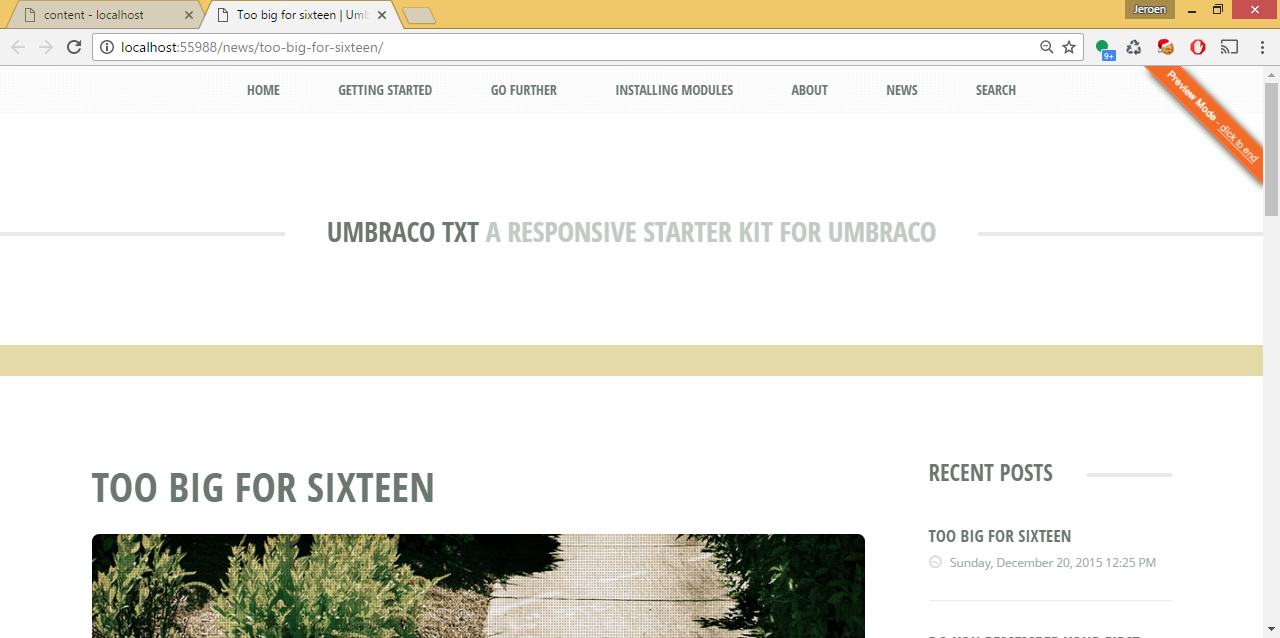
A special property editor will show the URL. Even if a node is unpublished. So for the 1-1 multilingual pages you can choose in what language you want to see the preview. Cache also needed to be cleared for the ContentFinders. Since the content editors do their Umbraco work on a separate server only the cache on that server will be cleared for the preview. This preview approach works very well for bigger projects.
The code
These commits in the example project show how you can preview all content:
- When the save button is pressed the entire website will go into preview. So it becomes easy to see all changes.
- If the save button is pressed it should clear the cache on that serve so the preview is up to date.
- Add event to hide the preview button because saving will make the website go into preview.
Search Vorto content
The story
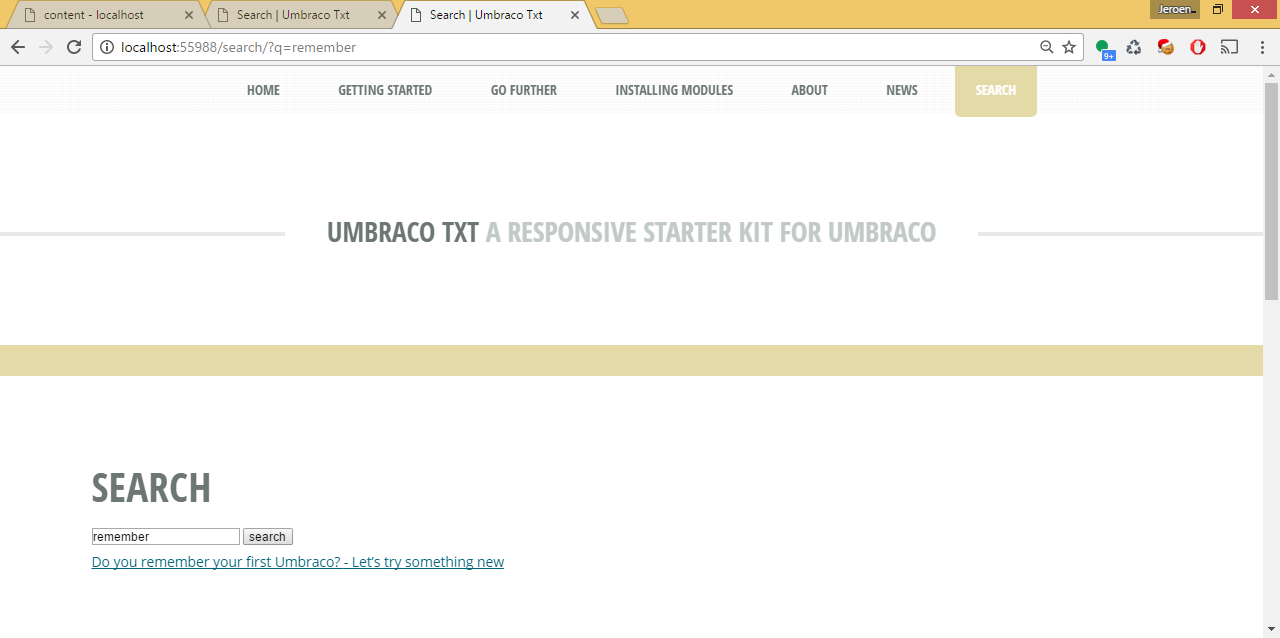
There are plenty of examples to search with Examine, but none of those examples showed how to index content that is inside Vorto. When you search for content in a specific language you don't want to get results from another language.
The topic
Someone else started a topic to search with Vorto.
The solution
With the GatheringNodeData event it's possible to add extra fields to indexes. So per language an extra field was added with the content of that language. The content is converted to an IPublishedContent because than it's much easier to get content per language from Vorto. With the help of some generic extract classes it's possible to iterate over all the node properties and decide per property what needs to be indexed. It's explained in more detail in the topic solution. All content per language is in a single field in Examine.
The search page needs a few tweaks. Fetch the current language of the page and use that to only search the language specific field in Examine.
The code
These commits in the example project show how you can search with Vorto:
- Started on event we need for indexing content.
- Added PropertyExtractResolver.
- Added all extract classes.
- Index all content per language.
- - Added empty search page. - Regenerated models.
- Added search logic. You can now search per language.
Convert IContent to IPublishedContent
The story
Sometimes having the content in Umbraco is not enough. A third party tool might need the content to translate it. The XML in the umbraco.config file contains ids and JSON which you don't want to export. Umbraco has a translation section, but it's heavily outdated so we need something custom. The code from the search Vorto content story indexes the same content which also needs to be exported. So the same technique with the generic extract classes can be used for this too. The extract classes need an IPublishedContent, but the content which needs to be exported could also be unpublished.
The topic
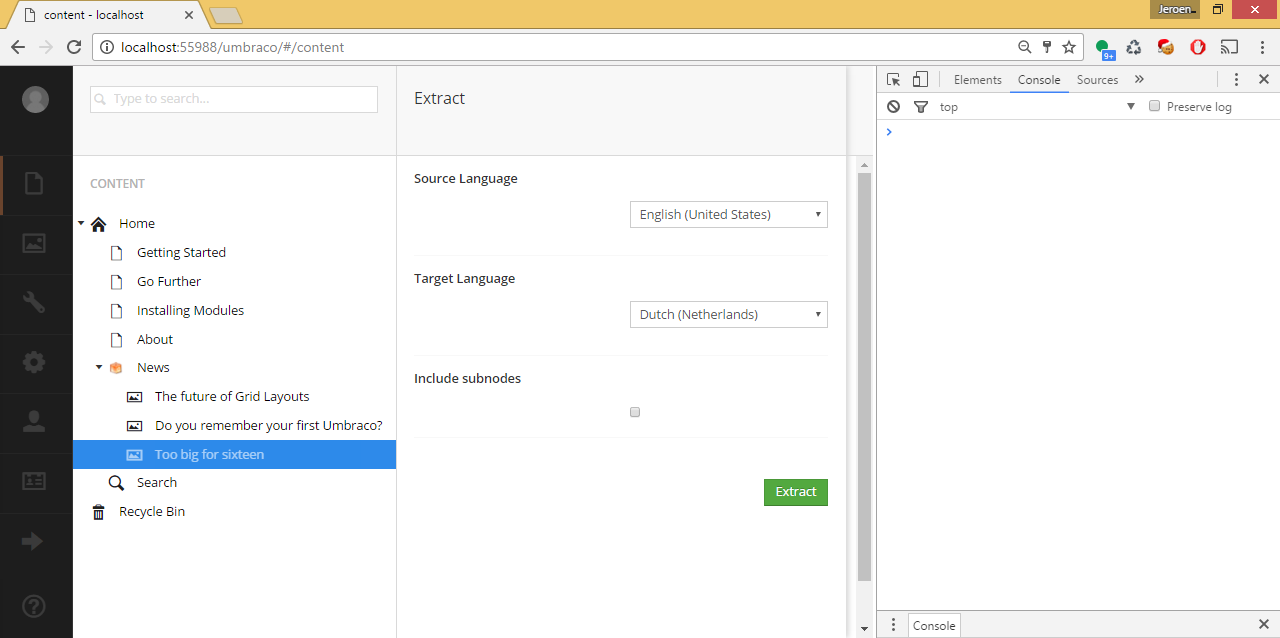
I started a topic if to ask if someone has some good ideas on how to get an IPublishedContent with unpublished data. So convert IContent to IPublishedContent.
The solution
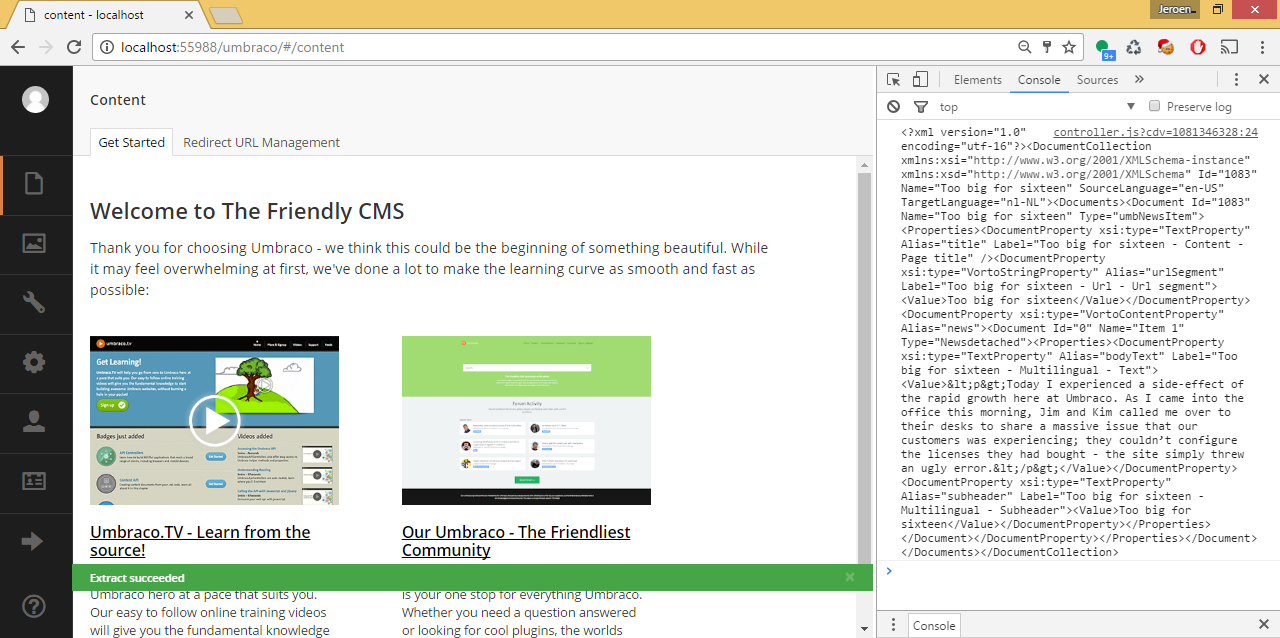
At the topic I got some good suggestions. One of them was from Stephan where he mentioned that the NuCache branch has code to do this. After making some changes to the code it was turned into an extension method. After extending the extract classes the content could be converted to XML with everything for a specific language that needs to be translated. With some extra AngularJS code this was turned into a menu action.
There are a lot more use cases where it's easy to have an IPublishedContent of an unpublished item. For example if you want to have a data source for nuPickers. You could create a dropdown which needs to show category nodes for a news article. The website might be unpublished so getting all this data for the dropdown could be hard with the IContent API. If you use IPublishedContent for this it's much easier. For example because you can use Property Value Converters.
The code
This gist shows the extension method.
This commit in the example project shows how can get translatable XML:
Examine indexes in Azure Blob Storage
The story
On a load balance environment it's possible that a new server is added which doesn't have the Examine index files yet. This means that Examine needs to reindex which can take a long time. So it would be better if the indexes are stored in a central place which can be shared between servers.
The topic
There is a long topic with issues of Examine on a load balance environment. Shannon has some possible solutions. Based on one of the solutions I started another topic called Using AzureDirectory with Examine.
The solution
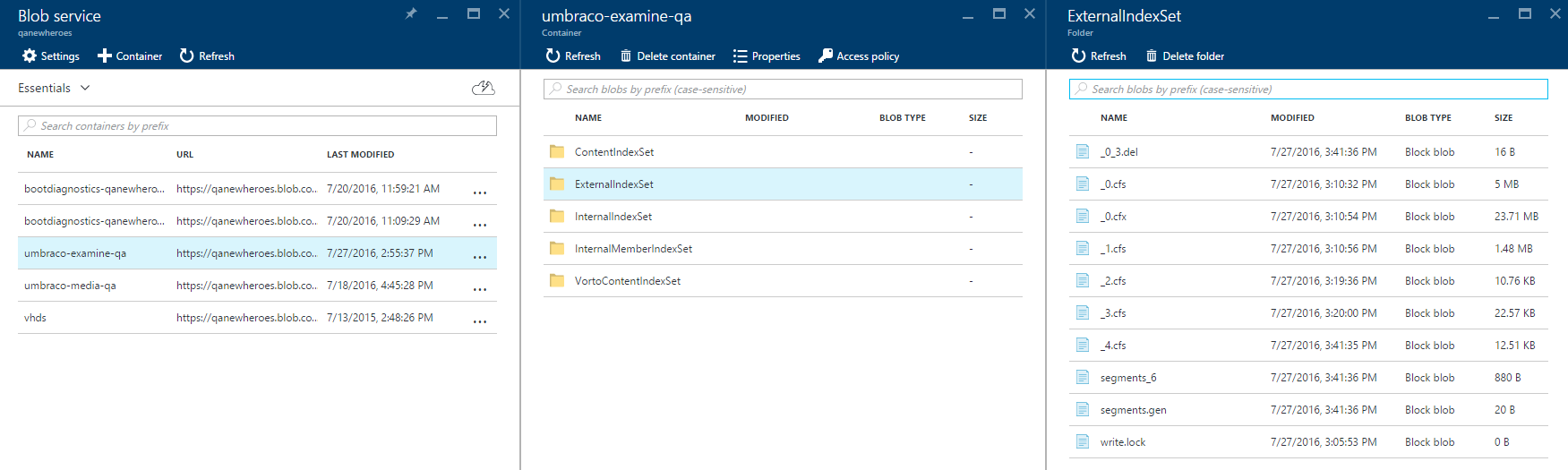
Since Examine 0.1.69? it's possible to implement IDirectoryFactory?. With the help of AzureDirectory you can store the Examine index files in Azure Blob Storage. This is working, but currently it's having some performance problems. The indexes are stored in blob storage, but they also have a local copy. Somehow when searching the local copy isn't always used and it could make a request to the blob storage. This hasn't been fixed yet and I hope Shannon Deminick? will be able to have a look at it soon.
Since there isn't a proper solution yet I started looking at alternatives. Azure Search seems be a nice replacement.
The code
There is a separate branch of the 1-1 multilingual example that runs on AzureDirectory.
These commit in the example project show how? you can have examine indexes in Azure Blob Storage:
Conclusion
Umbraco has always been very extensible. The above stories are proof of that. There are probably much more edge case stories out there. But no matter how crazy, it's always a good idea to start a topic. All the topics from the above stories have helped me in one way or another. Without the help of the community it wouldn't have been possible. So start a topic on our and ask for help. A tweet with #umbraco and a link to the topic might also help. And once you've found the solution update the topic so it can help others.
Sometimes a topic with same question already exists. So do some research before starting a new topic. The Umbraco source code is also a great place for research. For example for the preview all content story I discoverd an API that I needed by looking at the source code. And the source code of open source packages can also be very informative.
Wrap up
All the above stories are actually from a single customer. A large team at Colours has been working on the New Heroes project for a long time now. Even though it's been a very big project I thought it would be nice to backport some of these features to the 1-1 multilingual example project so others can learn from it.
This is the 5th year that I'm writing an article for 24 days in Umbraco. It's interessting to see how Umbraco has changed:
- 2012 DAMP Gallery
- 2013 Hybrid Framework
- 2014 Modify Umbraco URLs with the UrlProvider and ContentFinder
- 2015 1-1 Multilingual websites with Vorto and Nested Content
A lot of things weren't possible yet in Umbraco when I wrote the first article in 2012. It's good to see Umbraco has improved so much over the last couple of years and with v8 it will keep improving. Hopefully next year I'll be able to write a v8 article about some nice new features.
