The Content Tree is Dead
Heads Up!
This article is several years old now, and much has happened since then, so please keep that in mind while reading it.

"The content tree has been with us for as long as we can remember. We watched each other grow and have been together for a long time. Then we both became adults and expected too much from you. Now it's time to let each other go and start our own life..."
Content is exploding and the way we consume it is changing rapidly. Organisations are struggling to create the right context for their content. Using the content tree was always our primary tool for creating structure for both website visitor and content manager, but with personalization and omni-channel experiences being the standard for 2017 can we still go on managing content the way we always did? I disagree and now is the time to change our perspective on CMS editing.
When we take a look at how websites and webshops have changed over the last 5 years, the difference is stellar. Multi-device, responsive, personalized and connected websites are not unique anymore, they're the standard. When we take a look at how the CMS backend has changed over the last 5 years, minimal changes can be seen. Sure, there's a new skin and a better way of interaction with the content manager, but no fundamental changes in the way information is structured, indexed and presented.
The way we search and use information has changed significantly over the years as well. I immediately feel bothered when I see a telephone book or the Yellow Pages as they require you to browse for information. Ancient practices and unknown for kids growing up with tablets and smartphones. My 4-year old son even uses voice recognition to search on his tablet as he cannot write yet. Although our generation feels totally comfortable with our content tree, the next generation will have to learn using it and will therefore skip it alltogether.
Let's take a look at what we expect from information. It shouldn't be the end of the line anymore, presenting us with all the knowledge we are looking for. When the information is not sufficient or different from what we might expect, it should present us with the tools (search, links, products) to get to the right content. We don't ever want to browse anymore, searching for information, as it feels like we're wasting our time then. And who is to blame for not retrieving the right content? The website visitor won't blame himself for sure!
"Then why do we still go our way using that old content tree for structuring the information the old way?"
Next question is probably: "do we have a choice?". Yes we have. This year our company Arlanet put a lot of effort in implementing back-end solutions that provide this flexibility. Not because we want to make a living of this - we see it as the responsibility of the CMS supplier - but because it now slows our customers and therefore success of the solution down.
Let's take an example anyone can relate to: hospitals. You initially have some symptoms, which are part of the disease. For a group of diseases there are specialized units, who have both specialized as well as shared team members. The treatment to the disease had guidelines as well as a waiting list. All this content is related, one way or the other, in more that one A to B relation.
Nodes are related in the first degree from A to B, as well as B to A. Then B is related to C, as well as C is related to B. This makes A related to C in the second degree, as well as C related to A.
This might as Stephen Hawking explaining you the origins of the universe, but if you relate this to the example of the hospital, it makes sense. You have a disease (A) which has a treatment (B) that is carried out by a specialized unit (C) that has team members (D) that have waiting lists. When you search for a specialized unit you might want to show their team members. When you search on a disease you might want to see the waiting list. This should be common knowledge for both website and CMS when stored and managed in a non-hierarchical way.
Setting up a non-hierarchical content strategy will not mean freedom for all, you do want to set rules. It will be important to define each relationship to provide the right context. Content related to the second degree is more important than a relation in the fourth degree. If you do want to build your own solution to provide this, please make sure you set these relations both ways.
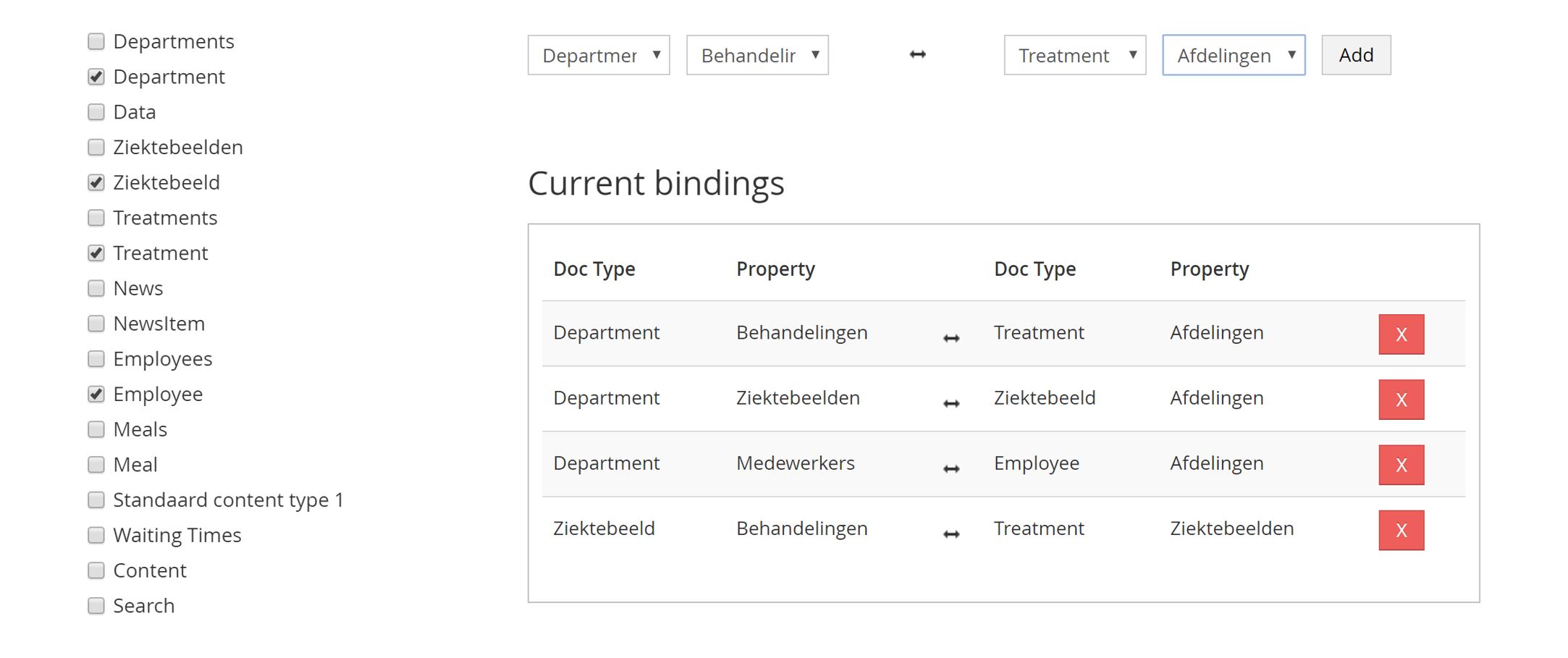
To extend the benefits of managing content in a non-hierarchical way the same context can be used for search purposes. If you search on the hospital website you might want to show second and third degree related information for the first three hits. You can also put search weight on each item and define relevance for search. This way you create relevant information from a perspective that is also understood and used by content managers without getting into technical detail.
So throw away the entire content tree and remove it from the CMS? As much as we would like to do this, the tree still has its use but in less complex environments. Hierarchical and non-hierarchical information can live next to each other. The content tree is useful for maintaining content lists and setting up simple relations.
We value the content tree as a friend from the past, with fond memories that will be revisited from time to time. But as your trunk has become so big, branches got so wide and leafs so many, let us take care of your roots. Together we will carry the weight you now have to carry alone. Let me afterwards sit in the tree again. Not to climb, but to enjoy the view and memories of the past.
Download the slides from the DUUG 16 Presentation.
Paul de Metter has been an internet entrepreneur for 20 years and started with his company Arlanet with Umbraco v2.1 back in 2005, being an Umbraco Certified Solution Partner since 2007. You can reach Paul at LinkedIn or by mail.
