SEO in Umbraco
Heads Up!
This article is several years old now, and much has happened since then, so please keep that in mind while reading it.
SEO-tab
Of course we start with the SEO-tab on the individual page. We have collected everything here, so the SEO-girl only has to go to this one place to change anything about SEO for the page. I think it is better, if the user never has to remember where to go. We used to have several tabs, one for each area, but they have been combined now.
Keywords
We have had a look at a lot of the keyword packages, but ended up rolling our own:
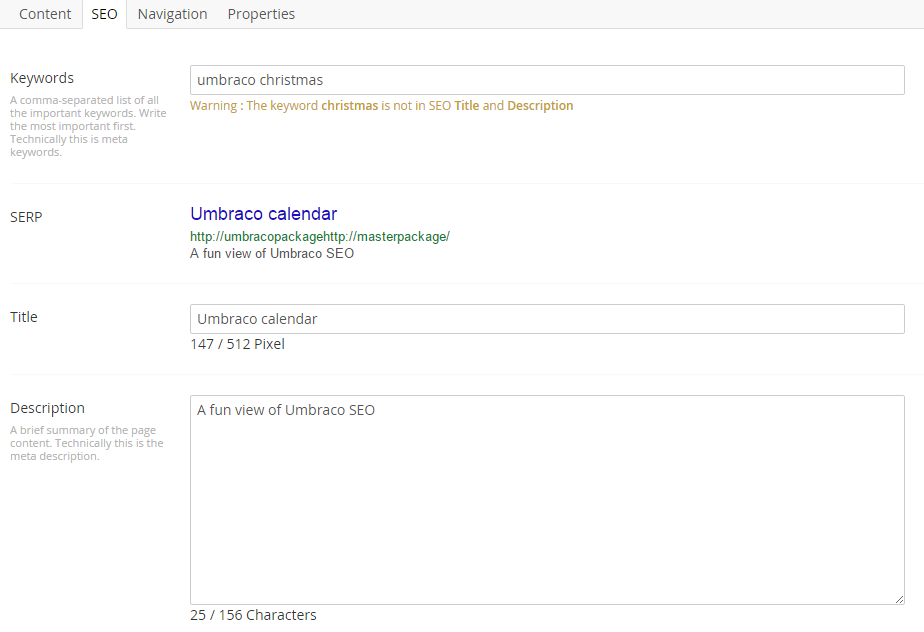
We have keywords, title, and description, each used in the standard way in the code. We have added an SERP-Preview, using the content from the other fields. We have also added a warning if any of the fields are empty, or if the keywords are not actually used. In our opinion, the keywords are not for Google, but simply a reminder for the editor for what the page should focus on.
We want to add some content validation too, but I cannot find a plugin that parses HTML5 correctly. As an example, in HTML5 you are actually allowed to have multiple <h1> on a page, as long as only one is in the main content, and the others are in asides, articles, etc. If anyone knows a plugin that can do this correctly, please mention it in the comments below.
You might notice, that we are using pixels for the title. Google actually uses pixels here, not characters as you will see in most SERP-previews.
Robots.txt per site
If you have ever done an Umbraco installation with more than one site, which includes multiple languages, you might have had this scenario:
The editor wants to block a specific URL from one of the sites, but not from the other one. If you simply add a robots.txt in the root folder, it will have effect on all sites in the installation.
To solve this, we have added a robots-node in the configuration of each site:
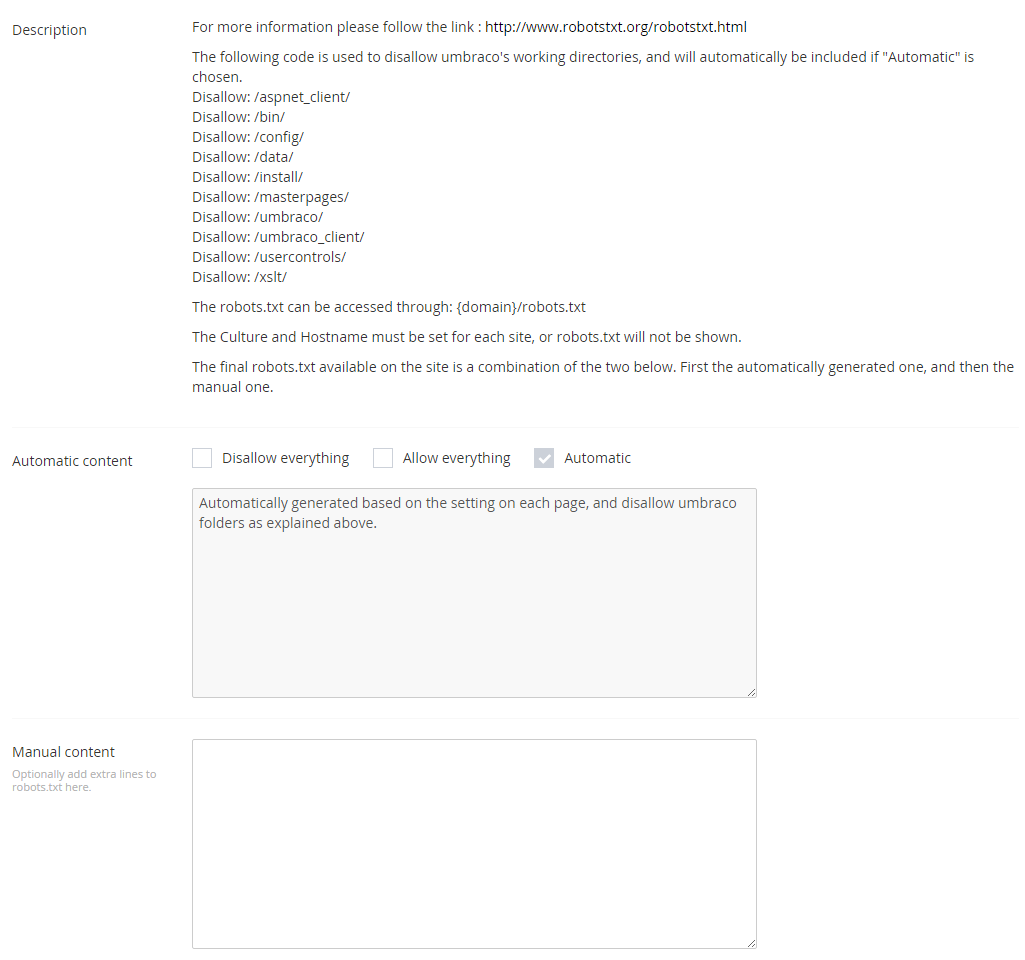
We have three settings.
- Disallow everything. We use this for our test environment, or on production before it goes live.
- Allow everything. We just include this so we don't get an SEO-guy telling us to add it later.
- Automatic. This will automatically block the list at the top of the page, as well as any pages the editor has decided to block - see below.
On top of this we have an area, where the SEO-guy can add extra lines, as needed.
As there is one of these nodes per domain, we have solved that problem.
Block a page in robots
As we create the robots.txt programmatically, we have also added a feature for the editor to block a page:
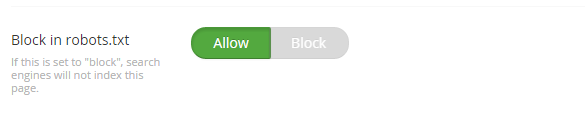
This does exactly what it says on the can.
Sitemap.xml per site
As we solved the robots.txt above, we thought we might have a look at the sitemap.xml too. The way it normally works, is that the admin uses an external tool to create a sitemap, and either add it manually to the search-engines, or add it to the root folder with all the same problems as above in thee robots.txt. On top of that, the sitemap will almost always be out of date. We actually have the essential information in Umbraco already, so why not just serve it:
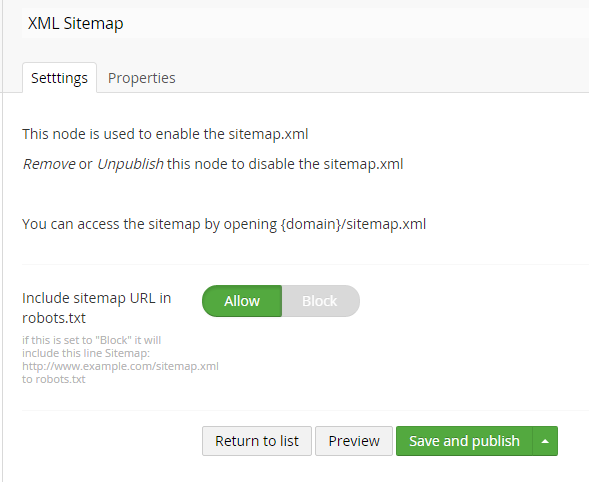
Of course we make sure to conform to the standards:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>http://umbracopackage/</loc>
<lastmod>2015-12-01T16:46:58+00:00</lastmod>
<changefreq>hourly</changefreq>
<priority>0.5</priority>
</url>
<url>
<loc>http://umbracopackage/page-2/</loc>
<lastmod>2015-11-17T09:15:01+00:00</lastmod>
<priority>0.5</priority>
</url>
</urlset>Now we have a sitemap that is always 100% up to date, and it is automatically included in the robots.txt too.
See about the extra settings below.
Sitemap settings per page
As you can see above, we have some extra information, that is not normally available in Umbraco. We have these settings on the SEO-tab for this:
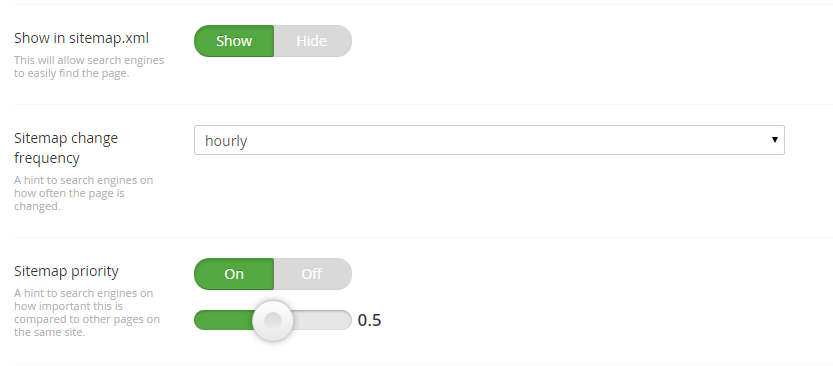
It is possible to hide the page from the sitemap, in case you want to, and you can change the rest of the settings outlined in the xml specification.
The location is obviously the link to the page, and last modified is last published. Nice and simple.
Noindex and nofollow on page
The final settings we have in the SEO-tab is whether the page should be indexed, and whether links should be followed:
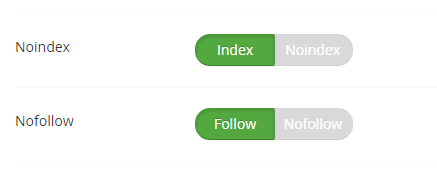
This will normally not be used, but we have the option, so we never have that request from an SEO company again. Of course it works just like you would expect.
Redirects and rewrites
By default any page in Umbraco can be opened with six urls:
- example.com/page
- example.com/page/
- example.com/page.aspx
- www.example.com/page
- www.example.com/page/
- www.example.com/page.aspx
This actually counts as duplicate content, so we want to stop that. I was going to write exactly what we do and why, but it turns out my source is last years calendar. Good job Niels Ellegaard - #h5yr.
Image alt and title texts
We have had a difficult time with this one. The default media picker in the RTE in Umbraco allows for an alt text (finally), but no title text. Some people suggest using the image name as the title text, but what would you do, if you want to use the same image in multiple places, but in different contexts? Or if you have multiple languages?.
We are using the grid, so we have stopped using the media picker in the RTE. If we need an image, we use our own picker, that allows alt and title texts directly on the settings flyout. If the editor clicks on an image on the page, this is the first thing she will see:
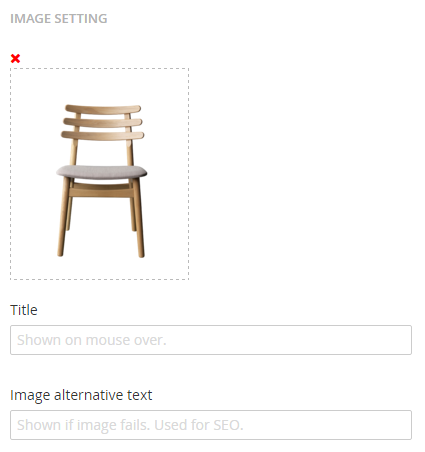
Of course, if there is more settings, like text overlay, it goes here too, but that is for another day. The main thing is, that we never have to talk to an SEO-guy about this again.
One thing to remember here: It is very important to escape the input in these fields. Let's say the title text is The bear's "tail" looks funny. Because there is both a single and a double quotation mark in there, the html of the page will break if it is not escaped correctly. We learned this the hard way.
Nofollow on links
We haven't had this requirement yet, so we have not implemented it, but at some point we will have some SEO-freak telling us, that he needs to control the follow/nofollow on individual links. When that happens, we will add another setting on the link picker just for this.
404-page
The standard 404-page from Umbraco has the same limitations as above. There is only one link in the configuration, but you might have multiple languages or sites. As far as I remember, it links to a node ID too, so the admin can break this unknowingly.
We have made a configuration for this, where the admin can choose what page is the 404-page. Simple as that:
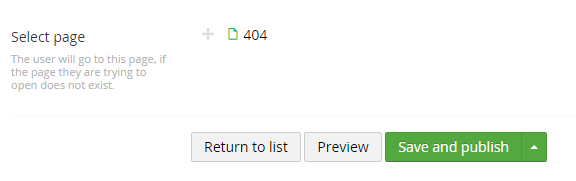
Accessing any url that does not exist on the site, will now open the 404-page, as expected. The admin should remember to block that page from robots.txt etc.
Final thoughts
I know it looks like a lot of the settings above can be combined, but it is my experience, that all SEO-companies have their own idea of what combination is best practice, and there is simply no way to change their mind. For this reason, we have given them the options in any combination they would like.
The normal editor can simply stay away from this tab, as we have set the default setting to the way a page would normally behave.
If you use the robots.txt and sitemap.xml as above, you have to careful about how you setup a page with multiple languages. If you have a host setting with example.com/de, the robots.txt will not work, as it needs to be in the root of the domain.
Some of the things above can be seen in action on our demo site. The login credentials are on the homepage. Note that the demo page runs an older version of our setup, so things will look slightly different from above.
Of course I'm happy to get any feedback, and if there is anything we have forgotten, please let me know.
